Technieken voor het bivariaat beantwoorden van een onderzoeksvraag
Inhoud:
Associatiematen
T-toets op een correlatiecoëfficiënt
Toets op Spearman's rangcorrelatiecoëfficiënt
T-toets op gepaarde waarnemingen
T-toets op twee gemiddelden
Eenwegs-variantieanalyse
Enkelvoudige regressie
Chikwadraattoets op het verband tussen twee nominale variabelen (kruistabellen)
Fisher-exact toets
Zie het overzicht van de associatiematen voor de keuze en interpretatie van associatiematen.
Met deze toets ga je na of de correlatie tussen twee variabelen in de steekproef voldoende sterk is om te mogen concluderen dat er ook een correlatie is in de populatie waaruit de steekproef is getrokken.
Bij een tweezijdige toets is de nulhypothese dat de correlatie in de populatie (aangegeven met de Griekse letter rho: ρ) nul is: H0: ρ = 0.
Statistische nulhypothese
De statistische nulhypothese is dat de correlatiecoëfficiënt in de populatie de waarde 0 heeft oftwel dat er in de populatie geen verband is.
H0: ρ = 0.
Voorwaarden
Beide variabelen moeten minstens op intervalniveau gemeten zijn. Daarnaast zijn er strikt genomen twee voorwaarden (bivariaat-normale kansverdeling en homoscedasticiteit) waar we in de praktijk meestal geen aandacht besteden. We controleren hier niet voor bij het vak IS. Houd er wel rekening mee dat de correlatiecoefficient geen goed beeld geeft van de samenhang wanneer die samenhang duidelijk niet rechtlijnig (lineair) is.
SPSS commando
- Een correlatiecoëfficiënt krijg je via het commando: ANALYZE - CORRELATE - BIVARIATE.
- In het dialoogscherm moet je de variabelen selecteren waartussen je de correlaties wilt weten.
- Onder CORRELATION COEFFICIENTS kun je aanvinken welke correlaties je wilt laten uitrekenen.
- Daaronder, bij TEST OF SIGNIFICANCE, kun je aangeven of je een tweezijdige (Two-tailed) of eenzijdige (One-tailed) overschrijdingskans wilt krijgen.
- Plak het commando in de syntax en laat het daar uitvoeren.
SPSS Output
De enige output is een kruistabel met de correlatiecoëfficiënten. Het significantieniveau van een correlatiecoëfficiënt wordt aangegeven met een of meer sterretjes (zie de noot bij de tabel). De overschrijdingskans staat direct onder de correlatiecoëfficiënt.
| Correlations |
| |
v4uur Hoeveel uur werkt u gemiddeld per week? |
v5uur Hoe lang kijkt u gemiddeld op een door de weekse dag televisie? Uren |
| v4uur Hoeveel uur werkt u gemiddeld per week? |
Pearson Correlation |
1 |
-,124** |
| Sig. (2-tailed) |
|
,000 |
| N |
1336 |
1334 |
| v5uur Hoe lang kijkt u gemiddeld op een door de weekse dag televisie? Uren |
Pearson Correlation |
-,124** |
1 |
| Sig. (2-tailed) |
,000 |
|
| N |
1334 |
1560 |
| **. Correlation is significant at the 0.01 level (2-tailed). |
Bij sommige andere commando's, zoals de t-toets op gepaarde waarnemingen, levert SPSS ook een toets op de correlatiecoëfficiënt.
Rapportage
Vermeld het volgende:
- De omvang van de correlatiecoëfficiënt. Maak duidelijk wat de twee variabelen en de eenheden zijn.
- De precieze overschrijdingskans. Wanneer de toets eenzijdig is, voeg je (eenzijdig) toe. NB de overschrijdingskans wordt altijd met 3 decimalen gerapporteerd.
Bijvoorbeeld: "Er is een significante correlatie, r = -0,12, p < 0,001, tussen het aantal uren dat Nederlanders werken en hoeveel uur ze doordeweeks naar de televisie kijken. Het verband is zwak en negatief: Nederlanders die meer uren werken, kijken minder televisie."
Rekenen voor excellentiegroep
Studenten in de excellentiegroep moeten de correlatiecoëfficiënt kunnen uitrekenen op grond van een datamatrix en de t-toets op een correlatiecoëfficiënt kunnen uitvoeren.
Wanneer variabelen duidelijk niet normaal verdeeld zijn, is het verstandig om via bootstrappen het betrouwbaarheidsinterval vast te stellen.
Indien de nulhypothese voor een toets op een correlatiecoëfficiënt een andere waarde dan 0 verwacht, kan de t-toets niet gebruikt worden en moet het bootstrap betrouwbaarheidsinterval gebruikt worden. Als het bootstrap betrouwbaarheidsinterval de waarde volgens de nulhypothese niet bevat, is een toets op deze nulhypothese significant.
Voorwaarden
Bootstrappen mag altijd toegepast worden wanneer de steekproef representatief is voor de populatie. Bij eenvoudige toetsen is dat in de praktijk al voldoende het geval bij een steekproef van enkele tientallen waarnemingen.
SPSS commando
- Voer de handelingen uit om een of meer correlatiecoëfficiënten (Pearson en/of SPearman) op te vragen in SPSS.
- Klik op BOOTSTRAP en kies de optie 'Perform bootstrapping'.
- Zet het aantal bootstrapsteekproeven bij voorkeur op 5000.
NB SPSS lijkt het bootstrappen bij elke toets uit te voeren totdat de optie 'Perform bootstrapping' weer wordt uitgezet.
SPSS Output
De gebruikelijke tabel met de Pearson of Spearman (rang)correlatie heeft nu extra rijen met de bootstrapresultaten: bias (het gemiddelde verschil tussen de waarden in de bootstrapsteekproeven en de waarde voor de oorspronkelijke steekproef), Std. Error (de standaardfout van de statistiek), en het betrouwbaarheidsinterval voor de statistiek.
NB een bootstrap op een (Pearson) correlatie kan veel computertijd vergen.
Rapportage
Wanneer je het betrouwbaarheidsinterval van de bootstraptoets rapporteert, voeg je (bootstrap) toe achter het gerapporteerde betrouwbaarheidsinterval.
Bijvoorbeeld: "Er is een significante correlatie, r = -0,12, 95%-CI[-0,16; -0,10] (bootstrap), tussen het aantal uren dat Nederlanders werken en hoeveel uur ze doordeweeks naar de televisie kijken. Het verband is zwak en negatief: Nederlanders die meer uren werken, kijken minder televisie."
Met deze toets ga je na of de rangcorrelatie tussen twee variabelen in de steekproef voldoende sterk is om te mogen concluderen dat er ook een rangcorrelatie is in de populatie waaruit de steekproef is getrokken.
Statistische nulhypothese
De statistische nulhypothese is dat de rangcorrelatie in de populatie nul is: H0: ρS = 0.
Voorwaarden
Beide variabelen moeten minstens op ordinaal niveau gemeten zijn.
Spearman's rangcorrelatie veronderstelt geen lineair (rechtlijnig) verband tussen de twee variabelen maar wel een monotoon (alleen maar stijgend of alleen maar dalend) verband.
SPSS commando
- Een rangcorrelatiecoëfficiënt krijg je via het commando: ANALYZE - CORRELATE - BIVARIATE.
- In het dialoogscherm moet je de variabelen selecteren waartussen je de correlaties wilt weten.
- Onder CORRELATION COEFFICIENTS kun je aanvinken welke correlaties je wilt laten uitrekenen. Kies hier 'Spearman'.
- Daaronder, bij TEST OF SIGNIFICANCE, kun je aangeven of je een tweezijdige (Two-tailed) of eenzijdige (One-tailed) overschrijdingskans wilt krijgen.
- Plak het commando in de syntax en laat het daar uitvoeren.
SPSS Output
De enige output is een kruistabel met de correlatiecoëfficiënten. Het significantieniveau van een correlatiecoëfficiënt wordt aangegeven met een of meer sterretjes (zie de noot bij de tabel). De overschrijdingskans staat direct onder de correlatiecoëfficiënt.
| Correlations |
| |
Hoeveel uur werkt u gemiddeld per week? |
Hoe lang kijkt u gemiddeld op een door de weekse dag televisie? Uren |
| Spearman's rho |
Hoeveel uur werkt u gemiddeld per week? |
Correlation Coefficient |
1,000 |
-,113** |
| Sig. (2-tailed) |
. |
,000 |
| N |
1336 |
1334 |
| Hoe lang kijkt u gemiddeld op een door de weekse dag televisie? Uren |
Correlation Coefficient |
-,113** |
1,000 |
| Sig. (2-tailed) |
,000 |
. |
| N |
1334 |
1560 |
| **. Correlation is significant at the 0.01 level (2-tailed). |
Rapportage
Vermeld het volgende:
- De omvang van de rangcorrelatiecoëfficiënt. Maak duidelijk wat de twee variabelen en de eenheden zijn.
- De precieze overschrijdingskans. Wanneer de toets eenzijdig is, voeg je (eenzijdig) toe. NB de overschrijdingskans wordt altijd met 3 decimalen gerapporteerd.
Bijvoorbeeld: "Er is een significante rangcorrelatie, rS = -0,11, p < 0,001, tussen het aantal uren dat Nederlanders werken en hoeveel uur ze doordeweeks naar de televisie kijken. Het verband is zwak en negatief: Nederlanders die meer uren werken, kijken minder televisie."
Rekenen voor excellentiegroep
Studenten in de excellentiegroep moeten de rangcorrelatiecoëfficiënt kunnen uitrekenen op grond van een datamatrix en de t-toets op de rangcorrelatiecoëfficiënt kunnen uitvoeren (als N > 30).
Met deze toets ga je na of er een verschil is tussen de gemiddelden van twee kwantitatieve variabelen die voor dezelfde eenheden (respondenten) gemeten zijn.
Statistische nulhypothese
De statistische nulhypothese is dat er geen verschil is tussen de gemiddelden van de twee variabelen in de populatie.
H0: μv = 0.
Bijvoorbeeld: kijken mensen in het weekeinde gemiddeld per dag meer televisie dan op een doordeweekse dag?
H0: μweekeinde = μdoordeweeks.
Voorwaarden
De kwantitatieve variabele is normaal verdeeld in de populatie waaruit de gepaarde steekproeven getrokken zijn of de steekproef bevat meer dan 30 paren.
Een eenvoudige maar beperkte controle op normaliteit vind je in de hint Controle op normale verdeling.
Je kunt beter een z-toets uitvoeren wanneer de steekproef minstens 100 waarnemingen bevat of wanneer de kwantitatieve variabele normaal verdeeld is in de populatie en de standaarddeviatie in de populatie is bekend. SPSS voert echter altijd een t-toets uit.
SPSS commando
- Om een t-toets op gepaarde waarnemingen uit te voeren kies je: ANALYZE - COMPARE MEANS - PAIRED-SAMPLES T-TEST.
- In het dialoogscherm kun je paren van telkens twee intervalvariabelen selecteren waarvan je de gemiddelden wilt vergelijken. Zorg er met de (linker) pijl voor dat de namen van de variabelen in de lijst komen onder 'Paired variables'. Met de pijlen rechts kun je de volgorde binnen en tussen de paren variabelen wijzigen.
- Klik op de knop OPTIONS. In het betreffende scherm kun je het betrouwbaarheidsinterval opgeven (de default is 95%). Ook kun je kiezen tussen het listwise of pairwise verwijderen van missende data.
- Plak het commando in de syntax en laat het daar uitvoeren.
SPSS Output
De belangrijkste output:
- De centrum- en spreidingsmaten voor beide variabelen. Met deze tabel kun je zien wat de gemiddelde scores zijn en welk gemiddelde (in de steekproef) hoger is. NB alle respondenten die op beide variabelen een score hebben, worden hier meegenomen.
Paired Samples Statistics
|
|
Mean |
N |
Std. Deviation |
Std. Error Mean |
|---|
| Pair 1 |
Hoe lang kijkt u gemiddeld op een door de weekse dag televisie? Uren |
2,0824 |
1555 |
1,61226 |
,04089 |
|---|
| Hoe lang kijkt u op zaterdag en zondag gemiddeld per dag televisie? Uren |
2,7797 |
1555 |
1,90792 |
,04838 |
|---|
- De tabel met de correlatie tussen de twee variabelen. Wanneer de twee variabelen niet significant correleren, is een t-toets voor gepaarde waarnemingen misschien niet zo handig omdat de scores dan niet onderling afhankelijk lijken te zijn.
Paired Samples Correlations
|
|
N |
Correlation |
Sig. |
|---|
| Pair 1 |
Hoe lang kijkt u gemiddeld op een door de weekse dag televisie? Uren & Hoe lang kijkt u op zaterdag en zondag gemiddeld per dag televisie? Uren |
1555 |
,638 |
,000 |
|---|
- De tabel met de resultaten van de t-toets. Eerst wordt het gemiddelde verschil tussen de twee variabelen gegeven (dat gelijk is aan het verschil tussen de gemiddelden van beide variabelen). Daarna wordt het betrouwbaarheidsinterval gegeven voor dit verschil. Wanneer nul niet in dit interval ligt, is het verschil significant, zoals ook afgelezen kan worden aan de overschrijdingskans onder "Sig. (2-tailed)".
Paired Samples Test
|
|
Paired Differences |
|
|
|
|---|
| Mean |
Std. Deviation |
Std. Error Mean |
95% Confidence Interval of the Difference |
t |
df |
Sig. (2-tailed) |
|---|
| |
|
|
Lower |
Upper |
|
|
|
|---|
| Pair 1 |
Hoe lang kijkt u gemiddeld op een door de weekse dag televisie? Uren - Hoe lang kijkt u op zaterdag en zondag gemiddeld per dag televisie? Uren |
-,69736 |
1,52119 |
,03858 |
-,77303 |
-,62170 |
-18,078 |
1554 |
,000 |
|---|
Rapportage
Vermeld het volgende:
- De gemiddelden (M) en standaarddeviaties (SD) van de twee variabelen. Maak ook duidelijk wat de variabele en de eenheden zijn.
- De waarde van de toetsingsgrootheid t, het aantal vrijheidsgraden (tussen haakjes, direct achter t) en de precieze overschrijdingskans. Wanneer de toets eenzijdig is, voeg je (eenzijdig) toe. NB de overschrijdingskans wordt altijd met 3 decimalen gerapporteerd.
- Vermeld het betrouwbaarheidsinterval (Confidence Interval, CI) van het gemiddelde.
- Wanneer de toets significant is, vermeld je ook de effectgrootte - Cohen's d - die je met de hand moet uitrekenen op grond van de SPSS output. SPSS berekent d namelijk niet voor je. Interpreteer het effect in termen van klein, middelmatig of groot.
Bijvoorbeeld: "Op een doordeweekse dag kijken Nederlanders gemiddeld 0,70 uur minder televisie (M = 2,08; SD = 1,61) per dag dan in het weekeinde (M = 2,78; SD = 1,91). Dit is een middelmatig statistisch significant verschil, t (1554) = -18,08, p = 0,000, CI = [-0,77, -0,62], d = 0,46."
Rekenen voor alle studenten
Reguliere studenten moeten de t-waarde van de steekproef, het gemiddelde verschil (Mv) en de standaardfout uit elkaar kunnen afleiden. Ook moeten zij uit de standaarddeviatie van het verschil (sv) en de omvang van de steekproef (N) de standaardfout kunnen berekenen. De relevante formule:
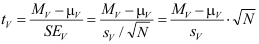
Verder moeten zij in de tabel met kritieke t-waarden kunnen opzoeken of een resultaat significant is op 5% (0,05), 1% (0,01) of 0,1% (0,001).
Zij moeten het betrouwbaarheidsinterval kunnen berekenen wanneer de standaardfout gegeven is, met de formule:
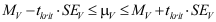 of
of 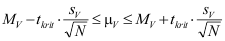
Ook moeten zij de eenzijdige overschrijdingskans kunnen berekenen uit de tweezijdige kans die SPSS geeft: deel de tweezijdige kans door 2 om de eenzijdige kans te krijgen.
Tenslotte moeten ze op grond van SPSS output de effectgrootte kunnen berekenen:
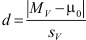 waarin de teller het absolute (dus positieve) verschil is tussen het gemiddelde verschil in de steekproef en het gemiddelde verschil in de populatie volgens de nulhypothese (meestal 0). Dit verschil staat in de SPSS tabel Paired-Samples Test onder Mean (althans wanneer de nulhypothese is dat μV = 0). De noemer, sV, is de geschatte standaardafwijking van de verschilscores in de steekproef, die in dezelfde SPSS tabel staat onder Std. Deviation.
waarin de teller het absolute (dus positieve) verschil is tussen het gemiddelde verschil in de steekproef en het gemiddelde verschil in de populatie volgens de nulhypothese (meestal 0). Dit verschil staat in de SPSS tabel Paired-Samples Test onder Mean (althans wanneer de nulhypothese is dat μV = 0). De noemer, sV, is de geschatte standaardafwijking van de verschilscores in de steekproef, die in dezelfde SPSS tabel staat onder Std. Deviation.
Hier is de effectgrootte bijvoorbeeld |-0,697| / 1,521 = 0,697 / 1,521 = 0,458.
Rekenen voor excellentiegroep
Studenten in de excellentiegroep moeten tevens de t-waarde en het betrouwbaarheidsinterval voor een steekproef kunnen uitrekenen op grond van een datamatrix.
Hiervoor moet eerst een verschilvariabele berekend worden. Van deze verschilvariabele is het gemiddelde nodig en de geschatte standaarddeviatie. De berekeningsformule voor de geschatte standaarddeviatie is:
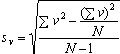
Voorwaarden
Bootstrappen mag altijd toegepast worden wanneer de steekproef representatief is voor de populatie. Bij eenvoudige toetsen is dat in de praktijk al voldoende het geval bij een steekproef van enkele tientallen waarnemingen.
SPSS commando
- Voer de handelingen uit om een t-toets op twee gemiddelden (gepaarde steekproeven) op te vragen.
- Klik op BOOTSTRAP en kies de optie 'Perform bootstrapping'.
- Zet het aantal bootstrapsteekproeven bij voorkeur op 5000.
NB SPSS lijkt het bootstrappen bij elke toets uit te voeren totdat de optie 'Perform bootstrapping' weer wordt uitgezet.
SPSS Output
Naast de gebruikelijke tabellen voor een t-toets worden twee extra tabellen met bootstrapresultaten gegeven.
De eerste tabel geeft betrouwbaarheidsintervallen volgens de bootstrapmethode voor het gemiddelde en de standaarddeviatie van elke variabele (meting).
De tweede tabel geeft het betrouwbaarheidsinterval voor het gemiddelde verschil tussen de twee metingen alsmede een overschrijdingskans voor het gemiddelde verschil dat in de oorspronkelijke steekproef is gevonden. Deze overschrijdingskans is niet altijd te vertrouwen.
Bovendien is de tabel met de correlatie tussen de twee metingen uitgebreid met een betrouwbaarheidsinterval op grond van de bootstrapmethode.
Rapportage
Wanneer je de overschrijdingskans of het betrouwbaarheidsinterval van de bootstraptoets rapporteert, voeg je (bootstrap) toe achter de gerapporteerde p-waarde of het betrouwbaarheidsinterval.
Bijvoorbeeld: "Op een doordeweekse dag kijken Nederlanders gemiddeld 0,70 uur minder televisie (M = 2,08; SD = 1,61) per dag dan in het weekeinde (M = 2,78; SD = 1,91). Dit is een statistisch significant verschil, t (1554) = -18,08, p = 0,002, CI = [-0,74, -0,63] (bootstrap)."
Met deze toets ga je na of er een verschil is tussen de gemiddelden van twee groepen eenheden (respondenten) op dezelfde kwantitatieve variabele.
Statistische nulhypothese
De statistische nulhypothese luidt dat de twee groepen gelijke populatiegemiddelden op de variabele hebben. Maak in de omschrijving van de groepen duidelijk om welke onafhankelijke variabele het gaat.
Voorbeeld: verschillen tussen mannen en vrouwen. H0: μvrouw = μman.
Je kunt ook schrijven: H0: μvrouw - μman = 0.
Voorwaarden
De kwantitatieve variabele is normaal verdeeld in de populaties waaruit de steekproeven getrokken zijn of de steekproef bevat voor elke groep meer dan 30 waarnemingen.
Een eenvoudige maar beperkte controle op normaliteit vind je in de hint Controle op normale verdeling.
Je kunt beter een z-toets uitvoeren wanneer elke steekproef minstens 100 waarnemingen bevat of wanneer de kwantitatieve variabele normaal verdeeld is in de populatie en de standaarddeviatie in de populatie bekend is. SPSS voert echter altijd een t-toets uit.
SPSS commando
- Om een t-toets op twee gemiddelden uit te voeren kies je: ANALYZE- COMPARE MEANS - INDEPENDENT-SAMPLES T-TEST.
- In het betreffende scherm kun je de interval variabelen selecteren waarvan je de gemiddelden wilt vergelijken voor verschillende groepen respondenten. Deze zet je de lijst Test Variable(s). Selecteer vervolgens de variabele die de twee groepen definieert waarvan je de gemiddelden wilt vergelijken, deze zet je in het vakje Grouping variable.
- Klik op de button 'DEFINE GROUPS' en geef aan welke waarden de groepen hebben (op de onafhankelijke variabele) die je wilt vergelijken.
- Klik op de knop OPTIONS. In het betreffende scherm kun je het betrouwbaarheidsinterval opgeven (de default is 95%). Ook kun je kiezen tussen het listwise of pairwise verwijderen van missende data.
SPSS Output
De belangrijkste output:
- De tabel met de groepsgemiddelden en standaarddeviaties. Deze tabel is nodig om straks te kunnen zeggen welke groep hoger scoort en hoe hoog de groepen scoren op de kwantitatieve variabele.
Group Statistics
|
Leeftijden in 2 groepen |
N |
Mean |
Std. Deviation |
Std. Error Mean |
|---|
| Hoe lang kijkt u op zaterdag en zondag gemiddeld per dag televisie? Uren |
jong |
756 |
2,7275 |
1,92710 |
,07009 |
|---|
| oud |
787 |
2,8189 |
1,88014 |
,06702 |
|---|
- De tabel met de resultaten van de t-toets. Let op, er worden twee verschillende resultaten gerapporteerd: "Equal variances assumed" en "Equal variances not assumed".
Wanneer de F-toets ("Levene's Test for Equality of Variances"), die in deze tabel gerapporteerd wordt, een significant resultaat heeft, mag je er niet van uitgaan dat de varianties in de twee groepen (in de populatie) gelijk zijn en moet je de resultaten voor de t-toets gebruiken achter "Equal variances not assumed". In de kolom 'Sig.' onder 'Levene's Test for Equality of Variances' vind je de overschrijdingskans van deze toets. Normaliter gebruik je een significantieniveau van 5% bij deze toets.
Is de F-toets niet significant (een sign. boven 0,05), dan mag je uitgaan van gelijke varianties en gebruik je de resultaten voor de t-toets achter "Equal variances assumed".
Independent Samples Test
|
|
Levene's Test for Equality of Variances |
t-test for Equality of Means |
|---|
| F |
Sig. |
t |
df |
Sig. (2-tailed) |
Mean Difference |
Std. Error Difference |
95% Confidence Interval of the Difference |
|---|
| |
|
|
|
|
|
|
Lower |
Upper |
|---|
| Hoe lang kijkt u op zaterdag en zondag gemiddeld per dag televisie? Uren |
Equal variances assumed |
,400 |
,527 |
-,943 |
1541 |
,346 |
-,09142 |
,09693 |
-,28154 |
,09870 |
|---|
| Equal variances not assumed |
|
|
-,943 |
1534,543 |
,346 |
-,09142 |
,09697 |
-,28164 |
,09880 |
|---|
Rapportage
Vermeld het volgende:
- De gemiddelden (M) en standaarddeviaties (SD) van de groepen. Maak ook duidelijk wat de variabelen en de eenheden zijn.
- De waarde van de toetsingsgrootheid t, het aantal vrijheidsgraden (tussen haakjes, direct achter t) en de precieze overschrijdingskans. Wanneer de toets eenzijdig is, voeg je (eenzijdig) toe. NB de overschrijdingskans wordt altijd met 3 decimalen gerapporteerd.
- Vermeld het betrouwbaarheidsinterval (Confidence Interval, CI) van het gemiddelde.
- Wanneer de toets significant is, vermeld je ook de effectgrootte - Cohen's d - die je met de hand moet uitrekenen op grond van de SPSS output. SPSS berekent d namelijk niet voor je. Interpreteer het effect in termen van klein, middelmatig of groot.
Bijvoorbeeld: "De jongeren kijken gemiddeld 2,7 uur televisie op een dag in het weekeinde (SD = 1,93) terwijl de ouderen gemiddeld 2,8 uur (SD = 1,88) kijken. Dit verschil is niet significant, t (1541) = -0,94, p = 0,346 , CI = [-0,28, 0,10]."
Rekenen voor alle studenten
Reguliere studenten moeten de t-waarde van de steekproef, het gemiddelde verschil (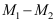 ) en de standaardfout uit elkaar kunnen afleiden. De relevante formule:
) en de standaardfout uit elkaar kunnen afleiden. De relevante formule:
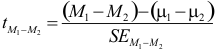
Verder moeten zij in de tabel met kritieke t-waarden kunnen opzoeken of een resultaat significant is op 5% (0,05), 1% (0,01) of 0,1% (0,001).
Zij moeten het betrouwbaarheidsinterval kunnen uitrekenen wanneer de standaardfout gegeven is, met de formule:
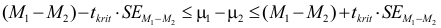
Ook moeten zij de eenzijdige overschrijdingskans kunnen berekenen uit de tweezijdige kans die SPSS geeft: deel de tweezijdige kans door 2 om de eenzijdige kans te krijgen.
Tenslotte moeten ze op grond van SPSS output de effectgrootte kunnen berekenen:
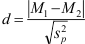 waarin de teller het absolute (dus positieve) verschil is tussen het verschil van de gemiddelden in de steekproef en het verschil van de populatiegemiddelden volgens de nulhypothese (meestal 0). Dit verschil staat in de SPSS tabel Independent Samples Test onder Mean Difference (althans wanneer de nulhypothese is dat μV = 0).
waarin de teller het absolute (dus positieve) verschil is tussen het verschil van de gemiddelden in de steekproef en het verschil van de populatiegemiddelden volgens de nulhypothese (meestal 0). Dit verschil staat in de SPSS tabel Independent Samples Test onder Mean Difference (althans wanneer de nulhypothese is dat μV = 0).
De noemer bevat de gepoolde variantie, sp2, die helaas niet door SPSS gerapporteerd wordt. Je moet deze gepoolde variantie eerst met de hand uitrekenen voordat je de formule voor de effectgrootte d kunt invullen.
De formule voor de gepoolde variantie bevat alleen de omvang van de twee steekproeven (n1 en n2) en de standaardafwijkingen in de twee steekproeven (s1 en s2), die je in de SPSS tabel Group Statistics kunt vinden. In dit voorbeeld:
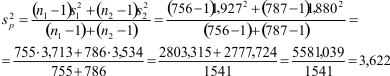
Hier is de effectgrootte dan:
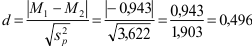
Rekenen voor excellentiegroep
Studenten in de excellentiegroep moeten de t-waarde, de standaardfout, de geschatte standaarddeviatie van het gemiddelde verschil voor een steekproef, de vrijheidsgraden en het betrouwbaarheidsinterval kunnen uitrekenen voor de situatie waarin de varianties gelijk zijn in de populatie en de situatie dat dit niet het geval is.
Bovendien moeten zij de F-toets kunnen uitvoeren om een keuze tussen deze twee situaties te maken. De formule (zie bivariaat beoordelen):
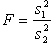
Verder moeten zij een z-toets op het verschil tussen twee gemiddelden kunnen berekenen.
Alle berekeningen moeten zij kunnen uitvoeren op grond van een datamatrix.
Voorwaarden
De permutatietoets mag altijd toegepast worden.
SPSS commando
- Ga naar ANALYZE>NONPARAMETRIC TESTS>LEGACY DIALOGS>2 INDEPENDENT SAMPLES.
- Selecteer de testvariabele en de variabele met de groepsindeling. Definieer de groepen net als bij een t-toets.
- Klik op EXACT en kies de optie 'Exact'.
- Om de gemiddelden en de standaardafwijkingen van de groepen te krijgen, bijvoorbeeld om de effectgrootte d te berekenen, kun je een t-toets uitvoeren, het commando ANALYZE>COMPARE MEANS>MEANS gebruiken of het commando ANALYZE>DESCRIPTIVE STATISTICS>EXPLORE.
SPSS Output
Naast een tabel met de rangen van de groepen, die niet van belang is omdat die alleen gebruikt wordt voor de Mann-Whitney toets, is er een tabel met toetsresultaten. Daarin is alleen van belang Exact Sig. (2-tailed) of Exact Sig. (1-tailed), afhankelijk van de vraag of je een tweezijdige of eenzijdige toets wilt uitvoeren.
Rapportage
Wanneer je de exacte overschrijdingskans van de permutatietoets rapporteert, voeg je exact toe achter de gerapporteerde p-waarde.
Bijvoorbeeld: "De jongeren kijken gemiddeld 2,7 uur televisie op een dag in het weekeinde (SD = 1,93) terwijl de ouderen gemiddeld 2,8 uur (SD = 1,88) kijken. Dit verschil is niet significant (p = 0,312 exact)."
Voorwaarden
Bootstrappen mag altijd toegepast worden wanneer de steekproef representatief is voor de populatie. Bij eenvoudige toetsen is dat in de praktijk al voldoende het geval bij een steekproef van enkele tientallen waarnemingen.
SPSS commando
- Voer de handelingen uit om een t-toets op twee gemiddelden (van onafhankelijke steekproeven) op te vragen.
- Klik op BOOTSTRAP en kies de optie 'Perform bootstrapping'.
- Zet het aantal bootstrapsteekproeven bij voorkeur op 5000.
NB SPSS lijkt het bootstrappen bij elke toets uit te voeren totdat de optie 'Perform bootstrapping' weer wordt uitgezet.
SPSS Output
Naast de gebruikelijke tabellen voor een t-toets worden twee extra tabellen met bootstrapresultaten gegeven.
De eerste tabel geeft betrouwbaarheidsintervallen volgens de bootstrapmethode voor het gemiddelde en de standaarddeviatie van elke groep.
De tweede tabel geeft het betrouwbaarheidsinterval voor het gemiddelde verschil (het verschil tussen de twee gemiddelden) alsmede een overschrijdingskans voor het gemiddelde verschil dat in de oorspronkelijke steekproef is gevonden. Deze overschrijdingskans is niet altijd te vertrouwen.
Rapportage
Wanneer je de overschrijdingskans of het betrouwbaarheidsinterval van de bootstraptoets rapporteert, voeg je (bootstrap) toe achter de gerapporteerde p-waarde of het betrouwbaarheidsinterval.
Bijvoorbeeld: "De jongeren kijken gemiddeld 2,7 uur televisie op een dag in het weekeinde (SD = 1,93) terwijl de ouderen gemiddeld 2,8 uur (SD = 1,88) kijken. Dit verschil is niet significant, t (1541) = -0,94, p = 0,327, CI = [-0,28, 0,10] (bootstrap)."
Met deze toets ga je na of er een verschil is tussen de gemiddelden van twee of meer groepen eenheden (respondenten) op dezelfde kwantitatieve variabele (minstens interval meetniveau). De indeling in groepen gebeurt met één onafhankelijke variabele: de factor in de variantieanalyse. De groepen heten ook de factorniveaus.
Statistische nulhypothese
De statistische nulhypothese luidt dat de groepen op de variabele gelijke populatiegemiddelden hebben. Maak in de omschrijving van de groepen duidelijk om welke onafhankelijke variabele (factor) het gaat. Je hoeft maximaal drie groepen expliciet te noemen.
Voorbeeld: verschillen tussen kranten. H0: μNRC = μVolkskrant = ... = μoverige kranten.
NB '...' staat hier voor alle niet genoemde kranten.
Voorwaarden
Het boek van Van Peet et al. specificeert 5 voorwaarden, waarvan er in de praktijk drie belangrijk zijn:
- De afhankelijke variabele moet minstens op interval niveau gemeten zijn.
- De groepen kunnen beschouwd worden als onafhankelijke steekproeven.
Variantieanalyse voor gepaarde waarnemingen bestaan ook, maar we behandelen dit niet in het vak IS.
- De groepen hebben gelijke varianties voor de afhankelijke variabele in de populatie.
Deze voorwaarde is alleen belangrijk wanneer de groepen niet ongeveer even groot zijn. SPSS rapporteert Levene's Test of Equality of Error Variances waarmee je kunt controleren of je van gelijke populatievarianties mag uitgaan.
SPSS commando
- Om een variantieanalyse uit te voeren met één onafhankelijke variabele kun je de volgende optie kiezen: ANALYZE - COMPARE MEANS - ONE-WAY ANOVA.
- In het betreffende scherm kun je de kwantitatieve (interval of ratio) variabele(n) selecteren waarvan je de gemiddelden wilt vergelijken voor verschillende groepen respondenten Deze zet je in de lijst Dependent. Selecteer vervolgens de variabele die de groepen definieert waarvan je de gemiddelden wilt vergelijken, deze zet je in het vakje Factor.
- Klik op de knop POST HOC. Als je wilt weten welke gemiddelden significant van elkaar verschillen en welke niet, dan gebruik je deze optie en vink je het vakje voor Bonferroni aan. NB dit is niet nodig wanneer er maar twee groepen vergeleken worden.
- Klik op de knop OPTIONS. In het betreffende scherm kun je kiezen tussen het listwise of pairwise verwijderen van missende data. Verder kun je beschrijvende statistieken van de variabelen opvragen, zoals het aantal cases, de standaard deviatie, enzovoort.
Het is de moeite waard om hier Descriptive aan te vinken, zodat je de gemiddelden van de groepen ziet.
Vink ook het vakje voor 'Means plot' aan. Dit geeft je een grafiek met de groepsgemiddelden waarin je eenvoudig ziet welke groep relatief hoog of laag scoort.
De optie homogeneity-of-variance-test voert Levene's test uit op de nulhypothese dat de varianties gelijk zijn in de populaties waaruit de steekproeven getrokken zijn.
SPSS Output
De centrale output is de samenvattende tabel met de resultaten van de variantieanalyse, die aangegeven wordt met ANOVA.
| ANOVA |
| na Houding t.a.v. roken na reclamecampagne |
| |
Sum of Squares |
df |
Mean Square |
F |
Sig. |
| Between Groups |
92,687 |
2 |
46,343 |
26,170 |
,000 |
| Within Groups |
170,000 |
96 |
1,771 |
|
|
| Total |
262,687 |
98 |
|
|
|
Deze tabel geeft:
- De kwadratensom (Sum of Squares) tussen de groepen die aangeven hoe groot de verschillen zijn tussen de gemiddelden van de groepen.
- De kwadratensom binnen de groepen, die aangeeft hoeveel foute of toevallige verschillen er zijn.
- De totale kwadratensom.
- De eerste twee kwadratensommen worden door hun vrijheidsgraden (df) gedeeld om het gemiddelde kwadraat te krijgen (Mean Square).
- De toetsingsgrootheid F is gelijk aan de gemiddelde kwadratensom tussen de groepen gedeeld door de gemiddelde kwadratensom binnen de groepen. Deze F toetst de nulhypothese dat alle groepsgemiddelden gelijk zijn (dat hun verschil nul is).
- De overschrijdingskans van deze toets staat onder Sig.. Een significant resultaat betekent hier dat de nulhypothese verworpen moet worden, dus dat er wel verschillen zijn tussen de groepsgemiddelden.
Wanneer Levene's toets op homogene varianties is opgevraagd, verschijnt het resultaat in een aparte tabel.
| Test of Homogeneity of Variances |
| na Houding t.a.v. roken na reclamecampagne |
| Levene Statistic |
df1 |
df2 |
Sig. |
| 5,501 |
2 |
96 |
,005 |
De toets is hier significant dus moeten we de nulhypothese verwerpen dat de groepen in de populatie dezelfde variantie hebben wat betreft hun houding ten aanzien van roken. Aangezien de groepen hier echter even groot zijn (zie de tabel Descriptives hieronder), mogen we toch een variantieanalyse uitvoeren.
Wanneer bij de OPTIONS ook Descriptives en 'Display means' is opgevraagd, wordt tevens een grafiek met de groepsgemiddelden getoond en een tabel met de gemiddelden, standaarddeviaties en dergelijke van alle groepen.
| Descriptives |
| na Houding t.a.v. roken na reclamecampagne |
| |
N |
Mean |
Std. Deviation |
Std. Error |
95% Confidence Interval for Mean |
Minimum |
Maximum |
| Lower Bound |
Upper Bound |
| 1,00 nee |
33 |
-,7576 |
1,00095 |
,17424 |
-1,1125 |
-,4027 |
-2,00 |
1,00 |
| 2,00 soms |
33 |
-1,4242 |
1,19975 |
,20885 |
-1,8497 |
-,9988 |
-4,00 |
1,00 |
| 3,00 vaak |
33 |
-3,0606 |
1,69447 |
,29497 |
-3,6614 |
-2,4598 |
-7,00 |
,00 |
| Total |
99 |
-1,7475 |
1,63722 |
,16455 |
-2,0740 |
-1,4209 |
-7,00 |
1,00 |
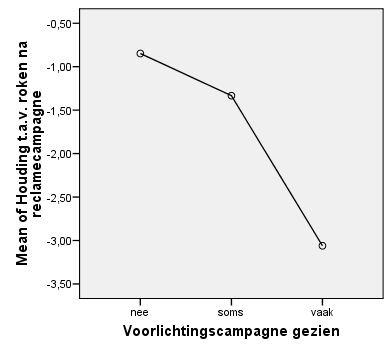
Wanneer er meer dan twee groepen zijn en bij Post Hoc is 'Bonferroni' opgevraagd, dan toont SPSS ook een tabel met significantietoetsen voor alle paarsgewijze vergelijkingen (Multiple Comparisons). We zien in dit voorbeeld dat er wel een significant verschil is tussen de groep die de voorlichting vaak gezien heeft en de andere twee groepen, maar dat er geen significant verschil is tussen de groep die de voorlichting niet of soms heeft gezien.
| Multiple Comparisons |
na Houding t.a.v. roken na reclamecampagne
Bonferroni |
| (I) behandeling2 Voorlichtingscampagne gezien |
(J) behandeling2 Voorlichtingscampagne gezien |
Mean Difference (I-J) |
Std. Error |
Sig. |
95% Confidence Interval |
| Lower Bound |
Upper Bound |
| 1,00 nee |
2,00 soms |
,66667 |
,32760 |
,134 |
-,1316 |
1,4649 |
| 3,00 vaak |
2,30303* |
,32760 |
,000 |
1,5048 |
3,1013 |
| 2,00 soms |
1,00 nee |
-,66667 |
,32760 |
,134 |
-1,4649 |
,1316 |
| 3,00 vaak |
1,63636* |
,32760 |
,000 |
,8381 |
2,4346 |
| 3,00 vaak |
1,00 nee |
-2,30303* |
,32760 |
,000 |
-3,1013 |
-1,5048 |
| 2,00 soms |
-1,63636* |
,32760 |
,000 |
-2,4346 |
-,8381 |
| *. The mean difference is significant at the 0.05 level. |
Rapportage
Vermeld het volgende:
- Vermeld het soort variantieanalyse dat je hebt uitgevoerd. Hier is dat de eenwegs-variantieanalyse voor onafhankelijke waarnemingen. Dit wordt ook wel ANOVA (ANalysis Of VAriance) genoemd.
- De samenvattende tabel met de resultaten van de variantieanalyse (de kwadratensommen, vrijheidsgraden, gemiddelde kwadraten, F-waarde en de overschrijdingskans) hoeft NIET getoond te worden. Wanneer je deze tabel niet toont, moet je het toetsresultaat vermelden in de interpreterende tekst: F (df1, df1) en p. Let op, je vermeldt twee vrijheidsgraden: eerst die van de teller (tussen groepen), dan die van de noemer (binnen groepen, fouten).
- Als het effect significant is, vermeld en interpreteer je ook eta2 (of met de Griekse letter: η2).
- Vermeld de gemiddelde scores van de groepen met de standaarddeviaties (in een tabel of in de interpreterende tekst) en maak duidelijk wat de eenheden en variabelen in het onderzoek zijn.
- Wanneer een post-hoc Bonferroni-toets is uitgevoerd, vermeld je tussen welke groepsgemiddelden er significante verschillen gevonden zijn. Vermeld zowel het gemiddelde verschil (Mverschil) als de bijbehorende overschrijdingskans (p).
- Wanneer de groepen niet ongeveer even groot zijn, vermeld je het resultaat van de test op homogeniteit van varianties (Equal Error Variances): F (df1, df1) en p.
Voorbeeld: "Er is een eenwegs-variantieanalyse voor onafhankelijke waarnemingen uitgevoerd. We vonden bij de proefpersonen een significant, groot effect van het zien van de voorlichtingscampagne op hun houding ten aanzien van roken, F (2, 96) = 26,17, p < 0,001, eta2 = 0,35. De proefpersonen die de voorlichtingsfilm niet gezien hadden, hebben de minst negatieve houding (M = -0,76, SD = 1,00) terwijl degenen die de film vaak hebben gezien de meest negatieve houding hebben (M = -3,06, SD = 1,69). De proefpersonen die de voorlichting soms zagen, scoren hier tussen in (M = -1,42, SD = 1,20). Uit een post-hoc meervoudige-vergelijkingentoets blijkt dat alleen het verschil tussen de proefpersonen die de voorlichting vaak zagen en de proefpersonen die deze niet (Mverschil = -2,30, p <0,001 ) of soms (Mverschil = -1,64, p < 0,001 ) zagen significant is. Er is geen significant verschil tussen de proefpersonen die de voorlichting niet of soms zagen."
Rekenen voor reguliere studenten
Je moet een SPSS tabel met de samenvattende resultaten (ANOVA) kunnen aanvullen wanneer er cijfers uit zijn weggelaten. Verder moet je eta2 kunnen uitrekenen op grond van de samenvattende tabel.
Een ANOVA tabel moet je verder kunnen invullen wanneer de kwadratensommen zijn gegeven (zoals hieronder). De vrijheidsgraden moet je kunnen afleiden uit informatie over de omvang van de steekproef (N) en het aantal groepen (factorniveaus) dat vergeleken wordt. Vervolgens moet je de gemiddelde kwadratensommen kunnen berekenen en daarmee de waarde van de toetsingsgrootheid F. Je kunt uit de formules op het formuleblad afleiden hoe je dit moet doen. De overschrijdingskans hoef je niet uit te rekenen maar je moet wel kunnen nagaan of het resultaat significant is op 5% met behulp van de significantietabellen.

Nadat de variantieanalyse is uitgevoerd, kan eta kwadraat (handmatig) uitgerekend worden, die aangeeft hoe sterk het effect is van de categorische variabele (groepsindeling) op de kwantitatieve variabele.
De formule is eenvoudig en kan direct ingevuld worden op grond van de samenvattende tabel:
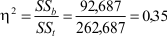
Eta kwadraat wordt geïnterpreteerd volgens de richtlijnen in het boek van Van Peet et al. (Tabel 10.4, blz. 247): 0,01 = klein effect, 0,09 = middelmatig effect, 0,25 = groot effect. In dit voorbeeld is er dus sprake van een groot effect (η2 = 0,35).
Rekenen voor excellentiegroep
Deelnemers in de excellentiegroep moeten een variantieanalyse met de hand kunnen uitrekenen op grond van een (kleine) datamatrix. Dit betekent dat je de kwadratensommen moet kunnen berekenen en vervolgens de samenvattende tabel (ANOVA) kunt opstellen. Zie pagina 247-249 in het boek van Van Peet.
Op het formuleblad staan ook berekeningsformules die eenvoudiger uit te rekenen zijn en een preciezer resultaat geven omdat je tussendoor minder hoeft af te ronden. Dat werkt als volgt.
Om een eenwegs-variantieanalyse uit te voeren, moet je twee van de drie kwadratensommen uitrekenen, bijvoorbeeld de totale kwadratensom (SSt) en de tussengroepenkwadratensom (SSb). De derde kwadratensom, hier de binnengroepenkwadratensom, is dan het verschil tussen de andere twee.
De formule voor de totale kwadratensom is:
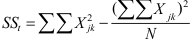
Hierin is het linker deel (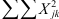 ) de som van de kwadraten van alle oorspronkelijke scores, terwijl het rechter deel (
) de som van de kwadraten van alle oorspronkelijke scores, terwijl het rechter deel (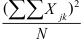 ) in de teller het kwadraat van de som van alle oorspronkelijke scores bevat. Je sommeert in beide gevallen over alle waarnemingen, dus over alle groepen en over alle waarnemingen binnen elke groep. Vandaar het dubbele sommatieteken Σ.
) in de teller het kwadraat van de som van alle oorspronkelijke scores bevat. Je sommeert in beide gevallen over alle waarnemingen, dus over alle groepen en over alle waarnemingen binnen elke groep. Vandaar het dubbele sommatieteken Σ.
In de datamatrix hoef je dus alleen de kwadraten van de oorspronkelijke scores toe te voegen en deze scores alsmede de oorspronkelijke scores te sommeren. Voor de berekening van de andere kwadratensommen is het handig om deze totalen per groep te berekenen en vervolgens bij elkaar op te tellen.
Toegepast op het voorbeeld uit het boek (p. 247), levert dit de volgende uitgebreide datamatrix op.
| SES |
Laag (XLaag) |
X2Laag |
Midden (XMidden) |
X2Midden |
Hoog (XHoog) |
X2Hoog |
|
2 |
4 |
6 |
36 |
5 |
25 |
|
4 |
16 |
4 |
16 |
6 |
36 |
|
6 |
36 |
7 |
49 |
4 |
16 |
|
5 |
25 |
4 |
16 |
3 |
9 |
|
5 |
25 |
7 |
49 |
6 |
36 |
|
4 |
16 |
5 |
25 |
9 |
81 |
|
1 |
1 |
3 |
9 |
6 |
36 |
|
2 |
4 |
5 |
25 |
8 |
64 |
|
2 |
4 |
3 |
9 |
7 |
49 |
|
3 |
9 |
7 |
49 |
9 |
81 |
| Som |
34 |
140 |
51 |
283 |
63 |
433 |
| n |
10 |
|
10 |
|
10 |
|
| M |
3,4 |
|
5,1 |
|
6,3 |
|
De formule van de totale kwadratensom kunnen we nu invullen door steeds de groepstotalen bij elkaar op te tellen.
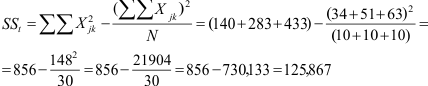
Mocht je op een negatief getal uitkomen, dan weet je dat je een rekenfout hebt gemaakt. Kwadraten kunnen niet negatief zijn en sommen van kwadraten dus ook niet.
Wanneer je de totalen per groep hebt uitgerekend, kun je nu ook de formule van de tussengroepenkwadratensom invullen.
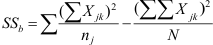
Als je goed kijkt, zie je dat het rechter deel van deze formule gelijk is aan het rechter deel van de formule voor de totale kwadratensom. Dit hebben we al uitgerekend (730,133) en kunnen we dus rechtstreeks invullen.
Het linker deel van de formule heeft in de teller het kwadraat van de som van de scores per groep gedeeld door het aantal waarnemingen in die groep. Die moeten we voor alle groepen optellen. De somscore per groep staat al in bovenstaande tabel, dus we kunnen de formule invullen:
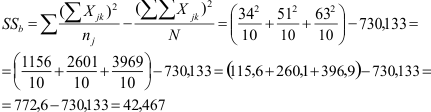
We kunnen nu de samenvattende tabel van een variantieanalyse invullen.
| |
Sum of Squares |
df |
Mean Square |
F |
| Tussengroepen |
(SSb) 42,467 |
(J - 1 = 3 - 1) 2 |
(42,467 / 2) 21,234 |
(21,234 / 3,089) 6,874 |
| Binnengroepen |
(SSw = SSt - SSb = 125,867 - 42,467) 83,4 |
(N - J = 30 - 3) 27 |
(83,4 / 27) 3,089 |
|
| Totaal |
(SSt) 125,867 |
(N - 1 = 30 - 1) 29 |
|
|
We kunnen nu op de gebruikelijke manier nagaan of de F-waarde van de steekproef (6,87) significant is door deze te vergelijken met de kritieke F-waarde bij (2, 27) vrijheidsgraden.
Meervoudige vergelijkingen voeren we uit voor hoofdeffecten wanneer er meer dan twee groepen zijn. Voer dan voor elk paar van groepen een t-toets op twee gemiddelden uit, waarbij je voor elke afzonderlijke toets het oorspronkelijke significantieniveau (bijvoorbeeld 5%) deelt door het totaal aantal t-toetsen (paren) dat je uitvoert. Kies in de significantietabel het dichtstbijzijnde significantieniveau.
Met deze toets ga je na of er een lineair verband is tussen twee kwantitatieve variabelen die gemeten zijn voor dezelfde eenheden (respondenten).
Zie de uitleg bij meervoudige regressieanalyse in dit werkboek.
Met deze toets ga je na of de verdeling van een categorische (nominale of ordinale) variabele verschillend is voor verschillende groepen. Anders gezegd, je gaat na of er een verband is tussen twee categorische variabelen.
Statistische nulhypothese
De statistische nulhypothese is dat er geen verband is tussen de twee variabelen in de populatie oftewel dat de twee variabelen statistisch onafhankelijk zijn.
We hebben geen Griekse tekens om deze nulhypothese mee uit te drukken aangezien het Griekse teken (chi oftewel χ) al voor de steekproef gebruikt wordt.
Voorwaarden
- 80% van de verwachte waarden van de cellen is minstens 5 en geen enkele verwachte waarde is kleiner dan 1.
- Minstens een van beide variabelen heeft minstens 3 categorieën.
Bij een 2x2 kruistabel wordt de Fisher-exact-toets gebruikt.
SPSS commando
De chikwadraattoets kan opgevraagd worden bij een kruistabel.
- Kies het commando ANALYZE-DESCRIPTIVE STATISTICS-CROSSTABS en plaats categorische variabelen in de vakken 'Row(s)' en 'Column(s)'.
- Kies 'Chi-square' onder STATISTICS en onder CELLS kies je zowel 'Expected' als 'Standardized' (dit laatste staat in het vakje 'Residuals') om straks te zien waar de verschillen zitten.
- Kies een associatiemaat die geschikt is om de sterkte van het verband te beschrijven.
Gebruik het keuzeschema van het vak Beschrijvende Statistiek.
- Plak het commando in het syntaxbestand en laat het lopen.
SPSS Output
De kruistabel met de verwachte frequenties (of de kolompercentages):
| v7 Welke krant leest U? * v1 Bent u een vrouw of man? Crosstabulation |
| |
v1 Bent u een vrouw of man? |
Total |
| 0 vrouw |
1 man |
| v7 Welke krant leest U? |
1 nrchandelsblad |
Count |
75 |
91 |
166 |
| Expected Count |
83,1 |
82,9 |
166,0 |
| Std. Residual |
-,9 |
,9 |
|
| 2 volkskrant |
Count |
110 |
112 |
222 |
| Expected Count |
111,1 |
110,9 |
222,0 |
| Std. Residual |
-,1 |
,1 |
|
| 3 telegraaf |
Count |
111 |
108 |
219 |
| Expected Count |
109,6 |
109,4 |
219,0 |
| Std. Residual |
,1 |
-,1 |
|
| 4 algemeendagblad |
Count |
53 |
60 |
113 |
| Expected Count |
56,5 |
56,5 |
113,0 |
| Std. Residual |
-,5 |
,5 |
|
| 5 trouw |
Count |
12 |
24 |
36 |
| Expected Count |
18,0 |
18,0 |
36,0 |
| Std. Residual |
-1,4 |
1,4 |
|
| 6 parool |
Count |
44 |
37 |
81 |
| Expected Count |
40,5 |
40,5 |
81,0 |
| Std. Residual |
,5 |
-,5 |
|
| 7 spits/metro |
Count |
208 |
178 |
386 |
| Expected Count |
193,1 |
192,9 |
386,0 |
| Std. Residual |
1,1 |
-1,1 |
|
| 8 nrc next |
Count |
40 |
38 |
78 |
| Expected Count |
39,0 |
39,0 |
78,0 |
| Std. Residual |
,2 |
-,2 |
|
| 9 anders |
Count |
118 |
122 |
240 |
| Expected Count |
120,1 |
119,9 |
240,0 |
| Std. Residual |
-,2 |
,2 |
|
| Total |
Count |
771 |
770 |
1541 |
| Expected Count |
771,0 |
770,0 |
1541,0 |
De waarde van chikwadraat en de overschrijdingskans:
Chi-Square Tests
|
Value |
df |
Asymp. Sig. (2-sided) |
|---|
| Pearson Chi-Square |
9,089(a) |
8 |
,335 |
|---|
| Likelihood Ratio |
9,172 |
8 |
,328 |
|---|
| Linear-by-Linear Association |
1,386 |
1 |
,239 |
|---|
| N of Valid Cases |
1541 |
|
|
|---|
| a 0 cells (,0%) have expected count less than 5. The minimum expected count is 17,99. |
Tenslotte wordt de associatiemaat getoond die je hebt opgevraagd, zoals je gewend bent van het vak Beschrijvende Statistiek. Omdat de krant wel gekozen kan worden op grond van het geslacht maar niet andersom, ligt een asymmetrische associatiemaat hier voor de hand: Lambda of Goodman en Kruskal's tau.
| Directional Measures |
| |
Value |
Asymp. Std. Errora |
Approx. Tb |
Approx. Sig. |
| Nominal by Nominal |
Lambda |
Symmetric |
.021 |
.014 |
1.472 |
.141 |
| Welke krant leest U? Dependent |
.000 |
.000 |
.c |
.c |
| Bent u een vrouw of man? Dependent |
.053 |
.035 |
1.472 |
.141 |
| Goodman and Kruskal tau |
Welke krant leest U? Dependent |
.001 |
.001 |
|
.370d |
| Bent u een vrouw of man? Dependent |
.006 |
.004 |
|
.335d |
a. Not assuming the null hypothesis.
b. Using the asymptotic standard error assuming the null hypothesis.
c. Cannot be computed because the asymptotic standard error equals zero.
d. Based on chi-square approximation
|
|
Rapportage
Vermeld het volgende:
- De waarde van chikwadraat met het aantal vrijheidgraden en de overschrijdingskans.
Bijvoorbeeld: Er blijkt geen significant verschil te zijn tussen mannen en vrouwen wat betreft de kranten die zij lezen, chikwadraat (8) = 9,09, p = 0,335.
- Wanneer er significante verschillen zijn gevonden, moet de sterkte van het verband benoemd worden en onder woorden worden gebracht waar de verschillen zitten.
Cellen waar de waargenomen frequentie significant hoger ligt dan de verwachte frequentie zijn combinaties die vaker voorkomen dan je op basis van toeval mag verwachten en waar de gestandaardiseerde residuen boven 1,96 liggen. Cellen waar het omgekeerde het geval is en waar de gestandaardiseerde residuen onder -1,96 liggen, zijn combinaties die minder vaak voorkomen dan je op basis van toeval mag verwachten.
Bijvoorbeeld: Het verband is (zeer) zwak (tau = 0,001). Mannen lezen het NRC relatief vaak terwijl vrouwen deze krant minder lezen dan op grond van toeval verwacht mag worden.
NB de gestandaardiseerde residuen zijn hier niet groter dan 1,96 of kleiner dan 1,96 omdat we hier geen significant verband hebben.
Rekenen voor reguliere studenten
Voor een cel in de kruistabel moet je de verwachte waarde en het gestandaardiseerd celresidu kunnen uitrekenen.
De verwachte waarde krijg je door het rijtotaal met het kolomtotaal te vermenigvuldigen en vervolgens te delen door het totaal van de hele kruistabel:
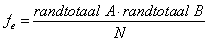 .
.
Het gestandaardiseerd celresidu krijg je door het verschil tussen de waargenomen en verwachte waarde te delen door de wortel uit de verwachte waarde:
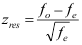 .
.
Rekenen voor excellentiegroep
De formule voor chikwadraat is (bekend van BS):
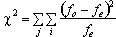
waarin fo de waargenomen frequentie van een cel aangeeft en fe staat voor de op basis van toeval verwachte frequentie.
Het aantal vrijheidsgraden is (k - 1)(r - 1) waarin r staat voor het aantal rijen in de kruistabel en k is het aantal kolommen.
De nulhypothese is dat beide variabelen in de populatie onafhankelijk zijn. We hebben hier geen wiskundige notatie voor.
Voorwaarden
De permutatietoets mag altijd toegepast worden.
SPSS commando
- Voer de handelingen uit om een kruistabel met chikwadraattoets op te vragen in SPSS.
- Klik op EXACT en kies de optie 'Exact'.
SPSS Output
De permutatietoets levert enkele extra kolommen op in de tabel met de chikwadraat-toetsresultaten. Van belang is de waarde voor Pearson Chi-Square in de kolommen Exact Sig. (2-tailed). Dit is de exacte tweezijdige overschrijdings volgens de permutatietoets.
Rapportage
Wanneer je de exacte overschrijdingskans van de permutatietoets rapporteert, voeg je exact toe achter de gerapporteerde p-waarde. Rapporteer de chi-kwadraatwaarde op de gebruikelijke manier omdat dit de toetsingsgrootheid is bij deze permutatietoets.
Bijvoorbeeld: "Er blijkt geen significant verschil te zijn tussen mannen en vrouwen wat betreft de kranten die zij lezen, chikwadraat (8) = 9,09, p = 0,264 (exact)."
Wanneer de verwachte frequenties te klein zijn om de chikwadraattoets uit te voeren, rekent SPSS voor een kruistabel met 4 cellen (2x2) automatisch de Fisher-exact toets uit. Voor grotere kruistabellen kun je de toets apart opvragen. Houd er dan rekening mee dat het even kan duren voordat SPSS klaar is met rekenen.
Statistische nulhypothese
De statistische nulhypothese is dat er geen verband is tussen de twee variabelen in de populatie oftewel dat de twee variabelen statistisch onafhankelijk zijn.
We hebben geen Griekse tekens om deze nulhypothese mee uit te drukken aangezien het Griekse teken (chi oftewel χ) al voor de steekproef gebruikt wordt.
Voorwaarden
Er zijn geen voorwaarden voor het gebruik van deze toets.
SPSS commando
De Fisher-exact toets kan opgevraagd worden bij een kruistabel.
- Kies het commando ANALYZE-DESCRIPTIVE STATISTICS-CROSSTABS en plaats categorische variabelen in de vakken 'Row(s)' en 'Column(s)'.
- Kies 'Chi-square' onder STATISTICS en 'Expected' onder CELLS om straks te zien waar de verschillen zitten. Je kunt de gestandaardiseerde residuen ook opvragen onder CELLS maar eigenlijk is dit overbodig omdat je in een 2x2 kruistabel weet waar de verschillen zitten wanneer chikwadraat significant is.
- Voor een 2x2 kruistabel wordt automatisch Fisher's exacte-waarschijnlijkheidstoets berekend. Voor een grotere tabel moet je onder EXACT de optie 'Exact' aanvinken. Let op, je moet ook 'Chi-square' onder STATISTICS kiezen (zie het vorige punt in deze lijst).
- Kies een geschikte associatiemaat.
- Plak het commando in het syntaxbestand en laat het lopen.
SPSS Output
De belangrijkste output: de tabel met de toetsresultaten, waarin de een- en tweezijdige overschrijdingskans van Fisher's test afgelezen kan worden.
Chi-Square Tests
|
Value |
df |
Asymp. Sig. (2-sided) |
Exact Sig. (2-sided) |
Exact Sig. (1-sided) |
|---|
| Pearson Chi-Square |
2,960(b) |
1 |
,085 |
|
|
|---|
| Continuity Correction(a) |
2,761 |
1 |
,097 |
|
|
|---|
| Likelihood Ratio |
2,962 |
1 |
,085 |
|
|
|---|
| Fisher's Exact Test |
|
|
|
,088 |
,048 |
|---|
| Linear-by-Linear Association |
2,958 |
1 |
,085 |
|
|
|---|
| N of Valid Cases |
1561 |
|
|
|
|
|---|
| a Computed only for a 2x2 table |
| b 0 cells (,0%) have expected count less than 5. The minimum expected count is 190,39. |
Rapportage
Vermeld het volgende:
- De overschrijdingskans van Fisher-exact.
Bijvoorbeeld: Er is een marginaal significant verschil tussen mannen en vrouwen wat betreft het lezen van het NRC (Fisher-exact p = 0,088).
- Als er een significant verschil is, rapporteer je welke combinaties (cellen) relatief veel voorkomen en hoe sterk het verband is.
Bijvoorbeeld: Relatief veel mannen hebben het NRC terwijl dat voor relatief weinig vrouwen geldt. Maar het verband is verwaarloosbaar klein (tau = 0,001).
Rekenen
Bij het vak IS zullen we de Fisher-exact toets niet met de hand berekenen.