Technieken voor het multivariaat bewerken van twee of meer variabelen
Inhoud:
Een schaal construeren in SPSS
Een index construeren
We gebruiken alleen Principale Componenten Analyse (PCA) als techniek om
schalen te construeren.
- Kies uit het menu: ANALYZE - DIMENSION REDUCTION - FACTOR.
- In het betreffende scherm dien je twee of meer variabelen te
selecteren
waarmee je een factoranalyse wilt uitvoeren. Selecteer de betreffende
variabelen door op de pijl te klikken naar het schermpje transporteren
waarboven staat variables. Om de schaalanalyse te laten uitvoeren dien
je op OK te klikken.
- Klik op de knop DESCRIPTIVES: Geeft je de mogelijkheid
beschrijvende statistieken op te vragen over de items. Dit is niet
nodig wanneer je vooraf de variabelen hebt beschreven en bewerkt.
- Klik op de knop EXTRACTION. Hiermee definieer je uit hoeveel factoren
(dimensies) de oplossing dient te bestaan. De
standaard instelling is: alle factoren waarvan de eigenwaarde hoger is
dan 1. In het begin is het beter deze instellingen niet te veranderen.
Vraag in dit dialoogscherm altijd het scree plot op.
- Klik op de knop ROTATION. De resultaten van factor-analyse
met varimax rotatie zijn vaak beter interpreteerbaar dan de
oorspronkelijke (ongeroteerde) oplossing. Deze kun je hier selecteren.
Het boek behandelt ook oblique rotatie, maar die zullen we niet
toepassen.
- Klik op de knop SCORES. Als je helemaal tevreden
bent met de door factor-analyse gegeven oplossing, kun je de scores van
respondenten op elk van de dimensies laten bewaren in de vorm van
nieuwe variabelen. Hier kun je dat opgeven. Bij IS gebruiken we deze
schaalvariabelen normaliter niet omdat we eerst de betrouwbaarheid van
de schaal willen bepalen.
Geef deze variabele naderhand (na de factoranalyse) labels die duidelijk
maken wat jouw interpretatie is.
- Klik op de knop OPTIONS: Biedt keuzes mbt het behandelen van missende
waarden en de presentatie van de uitkomsten. Het is voor de
interpretatie erg handig om hier onder Coefficient Display Format
het vakje Sorted by size aan te vinken.
- Klik op PASTE en laat de syntax daarna uitvoeren (RUN).
SPSS output
De belangrijke onderdelen van de output zijn:
- De tabel met communaliteiten geeft voor elk item het
percentage verklaarde variantie door alle geselecteerde componenten
samen. Deze getallen staan in de kolom Extraction. Ze laten zien
welk deel van de verschillen (variantie) in de antwoorden op de
oorspronkelijke vragen gedekt ('verklaard') worden door de geselecteerde
componenten.
Communalities
|
Initial |
Extraction |
| Ik game
omdat ? beter worden |
1,000 |
,900 |
| Ik game
omdat ? score verbeteren |
1,000 |
,972 |
| Ik game
omdat ?communiceren |
1,000 |
,792 |
| Als ik
game dan ? band voelen |
1,000 |
,902 |
Extraction
Method: Principal Component Analysis.
|
- De tabel met de eigenwaarden en percentages
verklaarde variantie voor elke component (inclusief de
niet-geselecteerde componenten). De eigenwaarden worden over de
niet-geroteerde oplossing berekend . Onder Initial Eigenvalues
staan de eigenwaarden van de componenten onder Total. Het meest
gebruikte criterium om componenten te selecteren, is dat ze een
eigenwaarde hebben die groter is dan 1.
De verklaarde varianties per component worden zowel voor de ongeroteerde
oplossing gegeven (onder Extraction Sums of Squared Loadings)
als voor de geroteerde oplossing gegeven (onder Rotation Sums of
Squared Loadings). Hier zie je hoe goed de geselecteerde
componenten de oorspronkelijke gegevens samenvatten. Dit kun je ook als
criterium gebruiken om componenten te selecteren: verklaren de
geselecteerde componenten minstens 70% van de totale variantie? Draagt
een component substantieel bij aan het percentage verklaarde variantie?
Total Variance Explained
|
Component |
Initial
Eigenvalues |
Extraction Sums of Squared Loadings |
Rotation
Sums of Squared Loadings |
| Total |
% of Variance |
Cumulative % |
Total |
% of Variance |
Cumulative % |
Total |
% of Variance |
Cumulative % |
| 1 |
1,964 |
49,107 |
49,107 |
1,964 |
49,107 |
49,107 |
1,743 |
43,568 |
43,568 |
| 2 |
1,081 |
27,015 |
76,122 |
1,081 |
27,015 |
76,122 |
1,302 |
32,554 |
76,122 |
| 3 |
,510 |
12,742 |
88,864
|
|
|
|
|
|
|
| 4 |
,445 |
11,136
|
100,000 |
|
|
|
|
|
|
| Extraction
Method: Principal Component Analysis. |
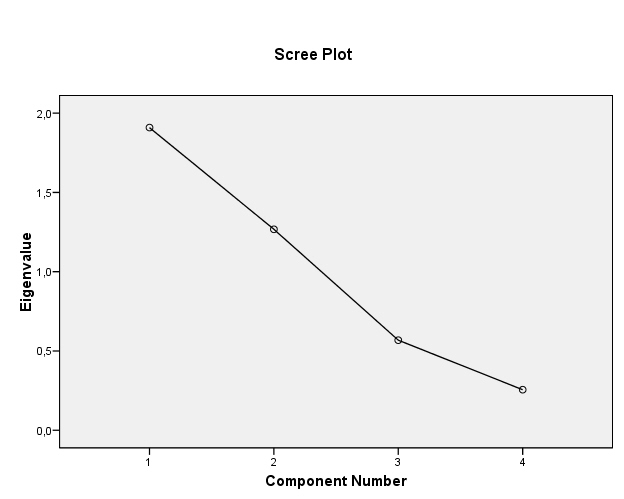
- Het scree plot is een visuele weergave van de eigenwaarden van alle
componenten. Hierin zie je hoeveel componenten relatief hoge
eigenwaarden hebben: de componenten 'boven' de knik in de grafiek. Dit
is een tweede criterium om het aantal componenten te kiezen. In
onderstaande grafiek is die knik (bij de 3e component) overigens niet
erg duidelijk.
- De tabel met de component matrix toont de componentlading
(of correlatie) van elk item met elke geselecteerde component na
rotatie. Wanneer er maar één component geselecteerd
wordt kan er niet geroteerd worden en gebruik je de (niet-geroteerde)
'Component Matrix'.
Rotated Component Matrix(a)
|
Component |
| 1 |
2 |
| Ik game
omdat ? beter worden |
,771 |
,356 |
| Ik game
omdat ? score verbeteren |
,546 |
,709 |
| Ik game
omdat ?communiceren |
,780 |
-,378 |
| Als ik
game dan ? band voelen |
,679 |
-,548 |
Extraction
Method: Principal Component Analysis.
Rotation Method: Varimax with Kaiser Normalization. |
| a
Rotation converged in 3 iterations. |
Rapportage
Zorg ervoor dat je de volgende onderdelen in je interpretatie hebt staan:
- Het soort factoranalyse: bij IS is dit altijd
principale-componenten-factoranalyse.
- De oorspronkelijke variabelen die gebruikt zijn.
- Het aantal factoren (componenten) met het selectiecriterium dat
gebruikt is en het totale percentage verklaarde variantie.
Lees
de eigenwaarde af aan de tabel "Total Variance Explained" in de kolom
"Total" onder "Initial Eigenvalues". De eigenwaarden horen bij de
ongeroteerde oplossing. Die gebruik je dus voor de selectie van het
aantal factoren.
In het scree plot zie je hoeveel componenten boven (links) van de knik
liggen.
Het
percentage verklaarde variantie van elke component lees je af aan de
tabel "Total Variance Explained": die zijn verschillend voor de
ongeroteerde en geroteerde oplossing. Je gebruikt die voor de
geroteerde oplossing (als die er is) omdat dit de oplossing is die je
inhoudelijk interpreteert (zie hieronder).
- Het soort rotatie: bij IS is dit altijd orthogonale (Varimax) rotatie.
- De tabel met componentladingen.
Dit is de tabel "Component Matrix", bij voorkeur de tabel "Rotated
Component Matrix".
- De benoeming van de factoren: jouw interpretatie van de dimensies of
constructen die de factoren vertegenwoordigen.
De
componentladingen geven de correlatie tussen de items en de component
(factor of dimensie). Kijk naar de items die hoog (positief of
negatief) laden op een factor (bijvoorbeeld minstens 0,45) en probeer
onder woorden te brengen wat
deze items gemeenschappelijk hebben.
Let op: wanneer items positief laden betekent dat dat
respondenten met een hogere score op deze items ook een hogere score
hebben op de schaal (component). Negatieve componentladingen geven het
omgekeerde aan: hogere scores op de items geven een lagere schaalscore.
Je moet ook kijken naar de betekenis van de waarden op de
oorspronkelijke items. Wanneer de items omgekeerd gecodeerd zijn,
namelijk dat een lagere score aangeeft dat men iets belangrijker vindt
of er meer mee eens is, dan betekent een hoge score op een component
waar deze items positieve ladingen op hebben, dat respondenten met een
hoge schaalscore juist het achterliggende abstracte concept onbelangrijker
vinden of het er meer mee oneens
zijn. Je moet de component dan liever benoemen als "hoe onbelangrijk
mensen iets vinden" of "gebrek aan belangstelling voor" dan "hoe
belangrijk mensen iets vinden" of "belangstelling voor".
Met een index vervang je een aantal variabelen door een nieuwe
variabele. Daarmee wordt echter geen abstract, niet direct meetbaar
concept gemeten, maar iets wat in principe concreet is en direct
gemeten zou kunnen worden. Bijvoorbeeld de totale tijd dat iemand naar
de publieke omroepen kijkt, kan eenvoudig berekend worden als de som
van de kijktijd naar Nederland 1, Nederland 2, Nederland 3, etcetera.
Een index is meestal gewoon een gemiddelde of totaalscore van
een respondent op een aantal variabelen. Je kunt een index daarom met
het commando COMPUTE creëren.
- Kies binnen het menu TRANSFORM de optie COMPUTE VARIABLE.
- Er
wordt een scherm geopend: "Compute variable". In het veld "Target
variable" voer je de naam in van de nieuwe variabele die je gaat
aanmaken, bijvoorbeeld "NLINDEX": het aantal uren dat iemand naar de 3
grootste publieke zenders kijkt per dag. Door op de knop "Type &
label" te klikken kun je labels toekennen.
- Nu wil je de formule definiëren om de waarden van
NLINDEX te berekenen. Stel dat we drie variabelen hebben die ieder het
aantal minuten geven dat iemand gemiddeld op een dag kijkt naar
Nederland 1 (totzend1), Nederland 2 (totzend2) en Nederland 3
(totzend3). We gaan nu eerst het aantal minuten optellen dat iedere
respondent naar NL1, NL2 en NL3 kijkt en dit totaal delen door 60. Dit
bereiken we door de som tussen haakjes te zetten. De formule die in het
veld "numeric expression" komt te staan luidt nu: "(totzend1 + totzend2
+ totzend3) / 60".
Je kunt dit doen door te typen of door de variabelen en symbolen te
selecteren met de muis.
- Als je klaar bent druk je op PASTE en in het syntaxscherm laat je het
commando vervolgens uitvoeren..
Let op: bij het COMPUTE commando kun je ook een groot aantal
voorgedefinieerde commando's gebruiken, bijvoorbeeld SUM() en MEAN()
die respectievelijk de somscore en de gemiddelde score berekenen over
de variabelen die je tussen de haakjes zet.
Deze commando's hebben de eigenaardigheid dat wanneer iemand een
missing value heeft op een van de variabelen, die variabele buiten
beschouwing wordt gelaten. De som en het gemiddelde wordt dan over de
resterende variabelen berekend. Dit kan vooral bij de somscore rare
resultaten opleveren.
Wanneer je iemand geen indexscore wilt geven wanneer die op een
of meer van de oorspronkelijke variabelen een misisng value heeft, moet
je zelf een formule voor de optelling (en deling) maken.
Rapportage
Je hoeft in de tekst alleen maar aan te geven welke formule je hebt
gebruikt om de index samen te stellen: een somscore, een gemiddelde, of
iets anders. Meestal kun je dit duidelijk maken in de naam die je aan
de index geeft.