Technieken voor het (univariaat) bewerken van één variabele
Inhoud:
Missende waarden en labels toekennen
Hercoderen van een bestaande variabele in een nieuwe
Een nieuwe variabele laten berekenen
Het selecteren van onderzoekseenheden
Het berekenen van z-scores
- Ga in het menu naar DATA - DEFINE VARIABLE PROPERTIES.
- Selecteer de variabele waarvan je de missende waarden wilt definiëren en klik op de pijl.
- Klik op de knop CONTINUE. Selecteer links de variabele. Rechts in het scherm verschijnen alle kenmerken van de variabele, zoals het label, de waarden, de valuelabels en de missende waarden.
- Het label van de variabele kan je rechtsbovenaan wijzigen.
- Je definieert een waarde als missende waarde door een vinkje te zetten voor een waarde in de kolom Missing.
- Het label van een waarde kan je achter de waarde in de kolom Label tikken.
- Klik op OK om de bewerking uit te laten voeren of op PASTE om de bewerking in het syntaxbestand op te laten slaan.
NB anders dan bij BS gebruik je nu dus de syntax om labels te geven aan variabelen en waarden (values). Deze syntax kun je een andere keer makkelijk herhalen.
- Het menu TRANSFORM bevat de optie RECODE.
- De optie RECODE kent twee opties. Onervaren gebruikers doen er goed aan altijd de optie INTO DIFFERENT VARIABLES te selecteren. Je bewaart dan altijd de oorspronkelijke gegevens mocht er iets misgaan (in het voorbeeld wordt DEM50 bewaard).
- Er is nu een nieuw scherm open. Selecteer de variabele die je wilt hercoderen in de linkerlijst (in ons voorbeeld DEM50) en klik op de pijl.
- DEM50 staat nu in de lijst Numeric variable -> Output variable
- Zet de cursor in het vakje Output variable - Name. Hier geef je de naam op van de nieuwe gehercodeerde variabele (bijvoorbeeld AGE).
- Klik nu in het Output variable - Label vakje. Hier kun je de nieuwe variabele een label geven, bijvoorbeeld "Leeftijd (recoded)". Klik nu op de button CHANGE. De naam van de nieuwe variabele staat nu in de lijst Numeric variable -> Output variable.
- Klik nu op "Old and new values". Er opent zich een nieuw scherm waarin je kunt opgeven hoe de waarden op de oorspronkelijke variabele moeten worden gehercodeerd in de nieuwe variabele.
- Klik op "Old value - Range" en type bijvoorbeeld een '0' in het linkervakje en een '12' in het rechtervakje (deze waarden hangen uiteraard af van de manier waarop de waarden gehercodeerd moeten worden). Vervolgens voer je een waarde in in het vakje New value - Value, bijvoorbeeld een '1' voor de eerste groep en klik op de button "Add". De waarden komen nu te staan in het scherm getiteld OLD -> NEW. Herhaal deze procedure voor elk van de groepen die je wilt vormen.
- Let op dat de categorieën niet mogen overlappen en dat je altijd waarden kunt weghalen uit het OLD -> NEW scherm door de betreffende waarden te selecteren en op de button "Remove" te drukken.
NB wanneer je onder "Old Value" een van de mogelijkheden kiest met "through" kun je wel dezelfde waarde gebruiken als bovengrens voor de ene klasse en als ondergrens van een andere klasse. Lees "through" als "tot en met": de waarde wordt gebruikt in de lagere klasse terwijl de hogere klasse begint met waarden die (net) hoger zijn dan deze grens.
- Als de lijst met te hercoderen waarden compleet is, dan druk je op de "Continue" button.
- Klik nu op "OK" en er wordt een nieuwe variabele aangemaakt met gehercodeerde waarden.
NB hercodeer alleen meer dan één variabele tegelijk wanneer alle variabelen op precies dezelfde manier gehercodeerd moeten worden. SPSS kan maar één hercodeerregel tegelijk uitvoeren, namelijk de laatste die je opgeeft.
- Kies binnen het menu TRANSFORM de optie COMPUTE.
- Er wordt een scherm geopend: "Compute variable". In het veld "Target variable" voer je de naam in van de nieuwe variabele die je gaat aanmaken, bijvoorbeeld "KijktijdUren". Door op de knop "Type & Label" te klikken kun je labels toekennen.
- Nu wil je de formule definiëren om de waarden van KijktijdUren te berekenen op grond van een variabele die de kijktijd in seconden geeft (KIJKTIJD). We moeten de oude variabele dus delen door 60 * 60 = 3600. Dit bereiken we door de volgende formule in het veld "numeric expression" te zetten: KIJKTIJD / 3600".
- Je kunt dit doen door te typen of door de variabelen en symbolen te selecteren met de muis.
- Als je klaar bent druk je op "OK".
- Ga naar het scherm met de data editor.
- Kies binnen het menu de opties DATA en SELECT CASES
- Nu verschijnt het scherm 'Select cases'.
- Kies de optie 'Select if condition is satisfied" en klik op de button "IF
". Nu opent zich een ander scherm: "Select cases: If".
- In het lege veld wil je aangeven welke analyse-eenheden (cases) geselecteerd moeten worden. Dit kan met gebruikmaking van de namen van de variabelen in de linkerlijst en de verschillende mathematische symbolen en getallen rechtsonder. Stel dat je alle respondenten wilt selecteren tussen de 18 en 29 jaar oud. In dat geval wil je dus alle cases selecteren waarvoor geldt dat DEM50 groter is dan 17 en kleiner dan 30.
- Klik nu eerst op de haakjes in het veld met getallen en symbolen.
- Selecteer vervolgens in de linkerlijst met variabelennamen DEM50. Klik nu op de pijl, waardoor DEM50 in het andere scherm tussen haakjes komt te staan. Type vervolgens het groter dan teken en het getal 17.
- Plaats nu de cursor buiten de haakjes en klik op het & teken. Nu herhaal je de vorige stappen, maar het tweede statement tussen haakjes wordt nu DEM50 < 30.
- In het veld staat nu: "(DEM50 > 17) & (DEM50 <30)".
- Klik op "Continue", en, teruggekomen in het vorige scherm op de knop: "OK".
- Je ziet nu dat in de data editor alle respondenten jonger dan 18 en ouder dan 29 zijn doorgestreept. In alle volgende analyses wordt met hun antwoorden geen rekening gehouden. Je kunt de selectie (eigenlijk: filter) weer opheffen door terug te gaan naar het "select cases
" menu en de optie "all cases" te selecteren.
Drie zaken zijn hier van belang:
- Controleer of je selectie gelukt is door na de selectie een frequentietabel te maken van de variabele(n) waarop je geselecteerd hebt. Daarin zouden alleen de geselecteerde waarden mogen voorkomen.
- Onervaren gebruikers doen er goed aan de optie "unselected cases are
deleted" niet te gebruiken. De niet geselecteerde analyse-eenheden worden hierdoor gewist en meestal wil je dat niet.
- Door middel van haakjes en logische AND en OR statements kun je analyse-eenheden selecteren op basis van combinaties van waarden op een groot aantal variabelen.
Om een variabele vergelijkbaar te maken met een andere variabele, kunnen we de variabele standaardiseren. We zetten de ruwe scores dan om in z-scores: we trekken de gemiddelde score van de ruw score af en delen door de standaarddeviatie van de variabele.
In SPSS kun je een nieuwe variabele laten maken met z-scores.
- Ga naar het scherm met de data editor.
- Kies binnen het menu de opties ANALYZE, daarbinnen DESCRIPTIVE STATISTICS en dan DESCRIPTIVES
- Nu verschijnt het scherm 'Descriptives'.
- Verplaats de variabele waarvan je z-scores wilt laten berekenen van het linker naar het rechter vak.
- Vink het vakje aan voor 'Save standardized values as variables'.
- Klik op OK.
- SPSS maakt nu onder andere nieuwe variabelen aan met z-scores, die de naam van de oude variabele hebben voorafgegaan door een Z.
Rapportage
Vermeld het volgende wanneer je een z-score van een respondent interpreteert:
- Wat de eenheden zijn en wat de variabele is.
De lezer moet begrijpen wat er gestandaardiseerd is.
- Hoeveel standaarddeviaties de respondent onder of boven het gemiddelde scoort.
Rekenen
Om de score van een respondent op een variabele om te zetten in een z-waarde moet je eerst het gemiddelde van de variabele aftrekken van de score en het resultaat vervolgens delen door de standaarddeviatie van de variabele.
Je hebt dus eerst het gemiddelde en de standaarddeviatie nodig. Je kunt deze berekenen op de manier die je bij MCO/BS geleerd hebt, de formules staan op het formuleblad.
Let op: we willen bij Inferentiële Statistiek altijd iets zeggen over de populatie op grond van een steekproef. Dan moet je een aangepaste formule gebruiken voor de standaardafwijking, de zogenoemde populatieschatting van de standaardafwijking, omdat de gewone standaardafwijking in de steekproef geen zuivere schatter is van de standaardafwijking in de populatie. Kort en goed: we delen door N - 1 in plaats van door N.
Rekenen voor excellentiegroep
In de MCO/BS methode om de standaardafwijking te berekenen, moet je tussendoor veel afronden wanneer je het gemiddelde aftrekt van elke ruwe score. Dit werkt onnauwkeurigheid in de hand.
Er zijn alternatieve berekeningsformules waarmee je minder hoeft af te ronden. Deze formules staan op het formuleblad voor de excellentiegroep. Je hebt dan de som van de scores op de variabele (ΣX) nodig en de som van de kwadraten (ΣX2) van de scores. Hieronder staat een voorbeeld.
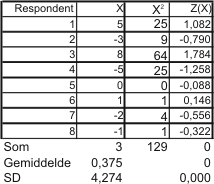
SPSS rekent altijd de geschatte spreiding uit, d.w.z. er wordt gedeeld door N - 1 in plaats van door N.
Om nu dezelfde uitkomst te krijgen, wordt hier de (reken)formule voor de populatieschatting van de standaardafwijking gebruikt.
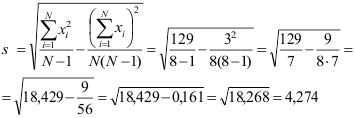
De z-score van bijvoorbeeld de eerste respondent wordt dan: (5 - 0,375) / 4,274 = 1,082.